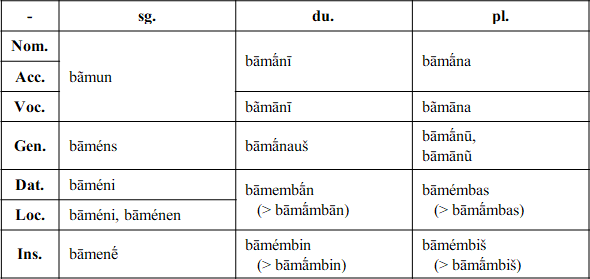
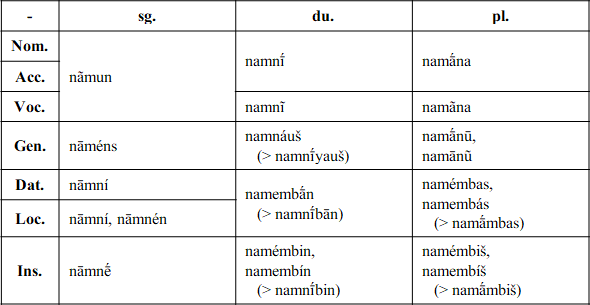
There seems to be a growing interest in Indo-European on the board, conlangs or natlangs, so I think it's the perfect time to post my own - a small language family of consisting of a proto-language (Proto-Tewanian) and it's three descendants (ATM known as language A, B and C).
There's already some snippets of information about them posted in a scratchpad thread, but I hope it will be OK to make a new one since the information there is outdated and not well presented.
I've been working on this language family for years, making bigger or smaller revisions - but only recently has the proto-language become stable enough so I can start working on it's descendants properly. Since the descendants are still in a state of flux, there will be no complete description of them here, but there will be an almost complete description of the proto-language.
I'm completely open to suggestions, in particular I would like to ask for resources to help me develop the languages' vocabulary.
2. Introduction to Proto-Tewanian
Proto-Tewanian, PTw. tewaniˑyakaˑ dujuˑš "Tewanian language", dujuˑš naˑs "our language", is a rather typical ancient Indo-European language, archaic in phonology but innovative in morphology. It's earliest developments show it to be an intermediate between Indo-Iranian and Hellenic, with some links to Albanian as well.
However, it was never meant to be spoken on Earth - it's origins lie in a comedy I wrote when I was a teenager, where uttering magic words can teleport you to a random place and time in the habitable universe (and that obviously happened to a whole Indo-European tribe). I decided to keep it that way to allow it to have a completely different environment to develop in.
It's most characteristic innovation is agglutinative morphology of verbs: while person-number (and case number) endings are still fusional, the rest of the verbal morphology is largely agglutinative. The main reason for this is that PTw. allows derived verb stems to be derived from other derived verbs stems, which other old IE. languages do not.
Another innovation of PTw. is the loss of distinction between imperfective and perfective aspects (first, they were reinterpreted as remote and recent past, the recent past later disappearing), with perfect aspect being preserved. As a consequence, PTw. lost nearly all traces of PIE. aorist. Proto-Tewanian has also innovated a future tense, as well as new perfective past and future tenses and perfect past and future tenses.
It has preserved the PIE. optative and innovated a conditional.
3. Phonology
3.1 Consonants
Code: Select all
CONSONANT INVENTORY
- lab. den. pal. vel.
-sib. +sib. –lab. +lab.
stops -vcd. p /p/ t /d/ k /k/ kʷ /kʷ/
+vcd. b /b/ d /d/ g /g/ gʷ /gʷ/
frics. -vcd. s /s/ š /ʃ/
+vcd. (z /z/) (ž /ʒ/)
africs. -vcd. c /ʦ/ č /ʧ/
+vcd. j /ʣ/ ǰ /ʤ/
nasals m /m/ n /n/
liquids l /l/
r /r/
semivow. y, i /j/ w, u /w/Sonorants, but not obstruents, can be geminated. This is represented by doubling the letter: <mm>, <nn>, <ll>, <rr>. Semivowels are represented as <y>, <w> when in onsent, as <i>, <u> when in coda, and as <iy>, <uw> when geminated.
Voiceless and voiced fricatives contrast with each other only in clusters with a stop, but not otherwise. That is /ps/, /pʃ/ and /kʃ/ contrast with /bz/, /bʒ/ and /gʒ/, but single /s/ and /ʃ/ don't contrast with single /z/ and /ʒ/.
Several synchronic and diachronic phenomena suggest that these clusters should be analysed together with the affricates /ʦ/, /ʧ/, /ʣ/ and /ʤ/, either all as clusters or all as affricates - they will be dealt with later.
3.1.1 Consonant allophones
When they don't participate in affricate-like clusters, the distribution between /s/, /ʃ/ and /z/, /ʒ/ is as follows: voiceless before a voiceless consonant, voiced before a voiced consonant (obstruent or sonorant). Word initially and after /n/ and /r/, voicing before a sonorant is inhibited
Code: Select all
s, ʃ > z, ʒ / _C[+vcd], !{#, n, r}_PTw. esmi "COP-1.sg.Pres." > [ˈɛzmɪ]
PTw. esti "COP-3.sg.Pres." > [ˈɛstɪ]
Intervocalically, voiced stops, but not voiced affricates, become voiced fricatives. This is one of the phenomena that suggest treating affricates together with clusters of stop and fricatives.
Code: Select all
b, d, g, gʷ > β, ð, ɣ, ɣʷ / V_VPTw. tagaibas "house-Dat.pl." > [ˈtaɣajβas]
PTw. sedaibas "chair-Dat.pl." > [ˈsɛðajβas]
Before a front vowels and /j/, velars (both plain and labialised), become palatals. Closer the vowel, stronger the palatalisation, but for simplicity, all these allophones will be represented as one.
Code: Select all
k, g, ɣ, kʷ, gʷ, ɣʷ > c, ɟ, ʝ, c[super]ɥ[/super], ɟ[super]ɥ[/super], ʝ[super]ɥ[/super] / _V[+front], jPTw. kʷiš "who" > [ˈcɥɪʃ]
3.2 Vowels
Code: Select all
VOWEL INVENTORY
- front central back
high iˑ/iː/ uˑ/uː/
i /ɪ/ u /ʊ/
mid ê /eː/ (ô /oː/)
e /ɛ/
low eˑ/æː/ a /a/ aˑ/ɑː/
overlong vowels: iː, êː, eː, aː, ôː, uːIn the last syllable of the word, Proto-Tewanian distinguishes three degrees of vowel length: short, long and overlong, represented as <V>, <Vˑ> and <Vː> respectively (I usually represent them by macrons and double macrons, Don Ringe's style, but the results of attempting that atrocity on this board are disastrous.).
Overlong vowels are usually the result of vowel contraction, so contracted vowels will be represented as overlong even where they don't contrast with long vowels, to simplify morphology.
3.2.1 Vowel allophones
Short front vowels [ɪ] and [ɛ] are raised when folowed by a /j/, with the resulting [ij] and [ej] becoming [iː] and [eː] when followed by a consonant.
Code: Select all
ɪ, ɛ > i, e / _j
ij, ej > iː, eː / _CPTw. pateres "father-Nom.pl." > [ˈpatɛrɛs]
PTw. pateyes "master-Nom.pl." > [ˈpatejɛs]
Before a tautosyllabic nasal, lax high vowels become tense.
Code: Select all
ɪ, ʊ > i, u / _N$PTw. sunuš "son-Nom.sg." > [ˈsʊnʊʃ]
PTw. sunun "son-Acc.sg." > [ˈsʊnun]
3.3 Timing and stress
Proto-Tewanian is mora-timed, and the rhythm of short, long and overlong syllables dominates it's prosody - primary stress is on the first syllable, with very light secondary stress on every heavy or superheavy syllable.
When counting morae, the following rules apply: a) short vowels count as one mora, b) each additional degree of length counts as one mora, c) coda sonorants, but not obstruents, count as one mora, d) syllables of more than three morae are prohibited, which is resolved by removing one degree of length from the syllable's nucleus vowel (Osthoff's rule). In practice, this means that in syllables closed by a sonorant, long vowels become short, and overlong vowels become long.
Code: Select all
V - 1 mora
Vː, VR - 2 morae
Vːː, VːR - 3 morae
3.4 Sandhi
Only external sandhi will be described here, since internal sandhi has been largely morphologises.
1. When two vowels meet at the edge of a word, the following rules apply:
a) After a high vowel or a semivowel, insert the corresponding semivowel
Code: Select all
0 > j / {j, ɪ, iː, iːː}_V
0 > w / {w, ʊ, uː, uːː}_Vb) Insert a /j/ before an initial front vowel, and a /w/ before an initial back vowel
Code: Select all
0 > j / V_V[+front]
0 > w / V_V[+back]When the first word ends in a consonant, following rules apply:
a) Devoice all word-final consonants
Code: Select all
C[+voiced] > C[-voiced] / _#b) Voice all word-final consonants and consonant clusters when followed by a voiced sound
Code: Select all
C[-voiced] > C [+voiced] / _#{V, C[+voiced]}Note that this rule applies to fricatives as well, making the rules of their voicing word-finally, different from the rules of their voicing word-internally - word, finally, they also voice intervocalically and when preceded by /n/ or /r/.
c) Assimilate voiced fricatives to the preceding sonorant
Code: Select all
mz, nz, lz, rʒ > mː, nː, lː, rː / _#Cd) shorten coda geminates and give the preceeding vowel one additional mora
Code: Select all
V(ː)Cː > V(ː)ːC / _#CWhen this happens, /ɪ/ and /ʊ/ become /iː/ and /uː/ before a nasal, and /eː/ and /oː/ before a liquid - this is the only situation where the vowel /oː/ appears outside of interjections.
Code: Select all
ɪNː, ʊNː > iːN, uːN / _#C
ɪRː, ʊRː> eːR, oːR / _#CWhile these rules may seem complicated at first, they are actually quite simple, as this example will demonstrate: word final [ins] is preserved before a voiceless consonant (and pause), becomes [inː] before a vowel and becomes [iːn] before a voiced consonant.
4. But what does the language really look like?!
To demonstrate all that has been said in action (especially sandhi), here's Schleicher's fable in three different versions. The first two versions are in Proto-Tewanian's usual orthography, one without sandhi, and one with sandhi - words that change between these versions have been bolded. The third version is in IPA, showing not just sandhi but all allophony.
Without sandhi:
Buwaˑt awiš, yasmi smi kismaˑna ne buwaˑnt. Awiš kʷe ecwans enakʷyaˑt : yan gʷeriˑyasun wajan wujaˑt, yan kʷe mejiˑyasun baran biraˑt, yan kʷe ǰemanun tekanti biraˑt.
Awiš kʷe ecwaibas mluwaˑt : "Ceˑr mai biˑdaˑsetai in enakʷyunnaˑn, yun ǰemuː ecwans ajeti."
Ecwans kʷe mluwaˑnt: "Taušiye, awê! Ceˑr naˑs biˑdaˑsetai in enakʷyunnaˑma, yun sai ǰemuː, patiš, awyêyaˑ wlanêyaˑ tepantaˑ westakaˑ webeti, awibas kʷe kismaˑna ne santi."
Awiš in taušiːnnaˑt, piltawiˑn kʷe bugaˑt.
With sandhi:
Buwaˑd awiš, yasmi smi kismaˑna ne buwaˑnt. Awiš kʷe yecwann enakʷyaˑt : yan gʷeriˑyasun wajan wujaˑt, yan kʷe mejiˑyasun baran biraˑt, yan kʷe ǰemanun tekanti biraˑt.
Awiš kʷe yecwaibaz mluwaˑt : "Ceˑr mai biˑdaˑsetaiy in enakʷyunnaˑn, yun ǰemuː wecwann ajeti."
Ecwans kʷe mluwaˑnt: "Taušiye, awê! Ceˑr naˑz biˑdaˑsetaiy in enakʷyunnaˑma, yun sai ǰemuː, patiš, awyêyaˑ wlanêyaˑ tepantaˑ westakaˑ webeti, awibas kʷe kismaˑna ne santi."
Awiž in taušiːnnaˑt, piltawiˑn kʷe bugaˑt.
In IPA:
ˈbʊwɑːd ˈawɪʃ |ˈjazmɪ zmɪ ˈcɪzmɑːna nɛ ˈbʊwɑːnt ‖ ˈawɪʃ cɥe ˈjɛʦwanː ˈɛnacɥjɑːt | ˈjan ˈɟɥɛriːjasun ˈwaʣan ˈwʊʣɑːt |ˈjan kɥɛ ˈmɛʣiːjasun ˈbaran ˈbɪrɑːt | ˈjan cɥɛ ˈʤɛmanun ˈtɛkantɪ ˈbɪrɑːt ‖
ˈawɪʃ cɥe ˈjɛʦwajβaz ˈmlʊwɑːt |ˈʦæːr maj ˈbiːðɑːsɛtaj ˈin ˈɛnacɥjunːɑːn |ˈjun ˈʤɛmuːː ˈwɛʦwanː ˈaʣɛtɪ ‖
ˈɛʦwans cɥɛ ˈmlʊwɑːnt | ˈtawʃijɛ | ˈaweː | ˈʦæːr nɑːz ˈbiːðɑːsɛtaj ˈin ˈɛnacɥjunːɑːma |ˈjun saj ˈʤɛmuːː | ˈpatɪʃ | ˈawjeːjɑː ˈwlaneːjɑː ˈtɛpantɑː ˈwɛstakɑː ˈwɛβɛtɪ |ˈawɪβas cɥɛ ˈcɪzmɑːna nɛ ˈsantɪ ‖
ˈawɪʒ ˈin ˈtawʃiːnːɑːt | ˈpɪltawiːn cɥɛ ˈbʊɣɑːt ‖
So, what can a reader expect if they continue following this thread? More complicated rules without sufficient examples? Of course! But they will also find out which name in Proto-Tewanian becomes Āegon in one descendant and Óin in another, as well as just how different from it's parent a descendant language can become!
That is, if their head doesn't explode first...
Edit: I've revised everything with examples and (unsuccessful?) attempts at humour.